I was drawn to post on this topic as an opportunity to reflect on and extend my previous experience as a photo archivist. Beyond an artistic interest in photography, I have always been interested in the life cycle of the digital image, whether it’s a digital surrogate of a physical object or born digital. And while the “magic” of digitization fades after you have scanned enough Kodachrome slides and photographed enough glass plate negatives, what is gained is an appreciation of the digital image, a binary representation, as something very much its own, and often still very fragile.
In an attempt to tackle the subject of image from a new perspective, I spent some time experimenting with Processing, a program (language?) I found relatively easy to work with. Understanding that digital images are simply another form of data, it was a useful exercise to reverse my interaction with the image in this way. Rather than looking at a file and seeing it first as a representation of a visual image, while only secondarily acknowledging that the the image is actually a sort of coded numeric representation, I started first with the code and then observed the image.
Initially, the images I generated by following some Processing tutorials were not much more sophisticated than something I might have created 20 years ago in Microsoft Paint:

Still, how gratifying to have created this by simply typing:
Of course, the site demonstrates examples of the level of sophistication possible with this program. While far from that skill level, a little time spent looking through the user gallery on Open Processing provided a number of examples of beautiful work that seem a bit more within reach. Though finding the extra hours in the day to build my Processing skills may just be another pipe dream, I’m not deleting the application any time soon. I admittedly found the instant gratification of entering code and viewing the results very satisfying.
While working through the tutorials and experimenting with Processing, I found myself wondering about the merits of the, well, process of creating images this way. Certainly many of these effects can be achieved through Photoshop and Illustrator. What can we learn about the digital image by bypassing the more user-friendly interface and working directly with code? In “Digital Ontologies: The Ideality of Form in/and Code Storage – or Can Graphesis Challenge Mathesis?” Johanna Drucker explores the relationship of human thought to its representations in various forms, and particularly within the digital environment. She asks:
“Is our conception of an image profoundly changed by its capacity to be stored as digital code? Or is the commonality of code storage as the defining condition of digital processing a confirmation of a long-standing Western philosophical quest for mathesis (knowledge represented in mathematical form, with the assumption that it is an unambiguous representation of thought), in which there ceases to be any ambiguity between knowledge and its representation as a perfect, symbolic, logical mathematical form?”
This week was light on reading, and if for any reason anyone is lamenting that fact and hasn’t read this article, I would recommend it. There is a lot to consider here, and I think Processing provides an apt environment for exploring image at the level of code. Drucker’s article reminded me that problems with the public perception of photographs as objectively truthful evidence date back to the very beginning of photography; in the digital environment, those problems are further complicated by public perception of code as objective, or somehow mathematically
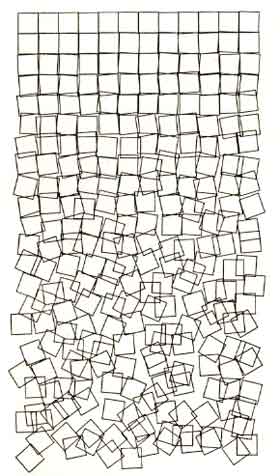
Georg Nees
“truthful,” rather than as language, authored by individuals, or groups of individuals, as we have discussed in class. After years of watching the light flashing in a scanner and painstakingly color-correcting images in order to most accurately represent the physical attributes of a photograph or print, and wondering what exactly it was that I was creating, I think I have more questions than answers when it comes to exploring the image as code (and ultimately as information), and I think this article is a useful starting point.
It’s also worth noting that one of the works Drucker considers, Georg Nees’ Schotter / Gravel Stones, created with a random number generator can be created in Processing by following this tutorial, which is a fun way to get a little more experience with the program.
I really liked that you thought about what the merit of making images this way is. What I find fascinating about these sorts of images (especially the ones that require a mouse button to be pressed) is that they both exist and don’t exist. If you print out an amazingly beautiful composition made with your code and frame it, that’s a digital artifact like taking a photograph of the Taj Mahal. The printed composition is sort of a record of a Shroedinger’s cat experiment. This time, when we ran the code, it did x. The next time we look at the code and run the piece, the fact that it once was x doesn’t impact it in any way. Maybe it will be x again, but most likely it will be x’ or y or sdfdsf. In this way, digital code art is super ephemeral, and that seems odd given how there’s a push to digitize archives in order to preserve them for posterity.