While I do believe that Ramsay does a good deal of work to prove how all manner of readings end up deforming their text(s), forming the “paratext” that a classmate described in another blog post, I still find myself unconvinced in attempting to understand how “distant reading” revolutionizes our understanding of how texts are experienced. This, of course, has a lot to do with my own academic training — I jumped ship from a PhD program in literature that loathed the push towards quantification and alignment with STEM disciplines as The Important Disciplines that is taking place all across universities (particularly state-funded ones).
My beef with distant reading has to do with the way in which it is so often employed, to produce word lists like these:
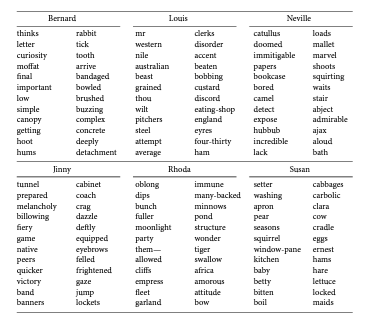
To further-articulate this beef: literary texts may be nothing more than an aggregate of words, but these words are always shaped by their given grammatical context! Our experience of literature hinges on much more than the lexicon of a given text. I believe that some of Ramsay’s own textual examples prove this point; a text like the I Ching is embedded within a tradition of Chinese literature and philosophy that makes use of a near-infinite polysignifying discourse (a popular example of this, articulated in linguistics texts and courses, has to do with how the word [ma], in Chinese, can mean either “mother,” “hemp,” “horse,” or “scold,” depending on context and the affixed tone). Or, regardless of how Ramsay seems to situate him, an author like Faulkner is challenging not for the number of unique lexical items in his vocabulary but because his syntax is always threatening to overflow the prescriptive limits of written English grammar (or so I believe).
Given my training as a de Manian, always looking at the way metonymy is playing out in a given text, I would be interested to see how natural language processing might be used in reference to literary syntax in order to better-uncover the workings of given lexical items in context. Such an approach might still be deforming, but it would certainly be less-deforming than the word-list approach. How might a computer deal with something like the first sentence from Ben Lerner’s second novel, 10:04?:
The city had converted an elevated length of abandoned railway spur into an aerial greenway and the agent and I were walking south along it in the unseasonable warmth after an outrageously expensive celebratory meal in Chelsea that included baby octopuses the chef had literally massaged to death.
It’s true that octopi and the notion of their “proprioception” appear all over Lerner’s text, but how do these figures play out within what Lerner calls the “prosody” of his sentences? Do computers yet distant-read syntax, and could they ever do so within the competing discourses of Prescriptive Written English and the infinite spoken varieties of the English language?
I agree with your point about the importance of context, and the ways in which word lists seem unable to account for context. Further, I wonder if these types of word lists can account for words meant to mean the same thing–they would be counted separately, but would potentially fail to convey an emphasis on a certain theme. I do think there’s something useful in them, though–as I mentioned, I think they provide a good starting point for further inquiry.
I have ambivalent feelings when approaching the Ramsay text. It seems like a very tricky position to academically inhibit, and certainly humanistic discourses are resistant to “algorithmic criticism”, for the great reasons that you’ve listed. I think my original fear was that it promoted an artificial form of intelligence that could only function on a superficial level that need not push further the depths of academic insights. However, I do find it quite interesting through programs such as ELISE, etc… can promote a different heuristic within “human based criticism with computers” (81), however what that heuristic translates into remains to be seen. The precedent to move towards the digital seems an inevitable, yet humanistic discourse wants to deny said fact. It’s interesting (I guess I don’t have much to say or quite a language to say it), but could be the next big issue for we academics to crunch on.