I’m very pleased to be investigating the DFR elements built into JSTOR. Adding and removing constraints seems much like constructing any regular JSTOR search. Reading Ramsay reminds me that the chart options, revealing disciplinary origin of texts and similar metadata, are themselves paratexts, intermediaries between the invention and application of constraints to a corpus and the more typical critical activity of interpreting the results. Ramsay writes of a word count table, for example, “The list is a paratext that now stands alongside the other, impressing itself upon it and upon our sense of what is meaningful” (12).
Perhaps it’s worth mentioning that JSTOR as a corpus has been methodically coded (thank you for that labor, someone!) so that its texts are legible to algorithmic search protocols. For some purposes, such as questions about which disciplines might be most engaged with certain topics, the “distant reading” of its data visualizations may of course be more informative than traditional language-driven engagement with specific texts.
I received my data promptly from JSTOR, perhaps because my query (basically: refugees, freedom of movement, and middle east) only produced 29 hits. I’m still a bit unclear about the meaning of the various n-grams, though I suspect the # symbol comes to stand in for one of my search terms? By the way, this ngram-viewer is a thing on Google Books:
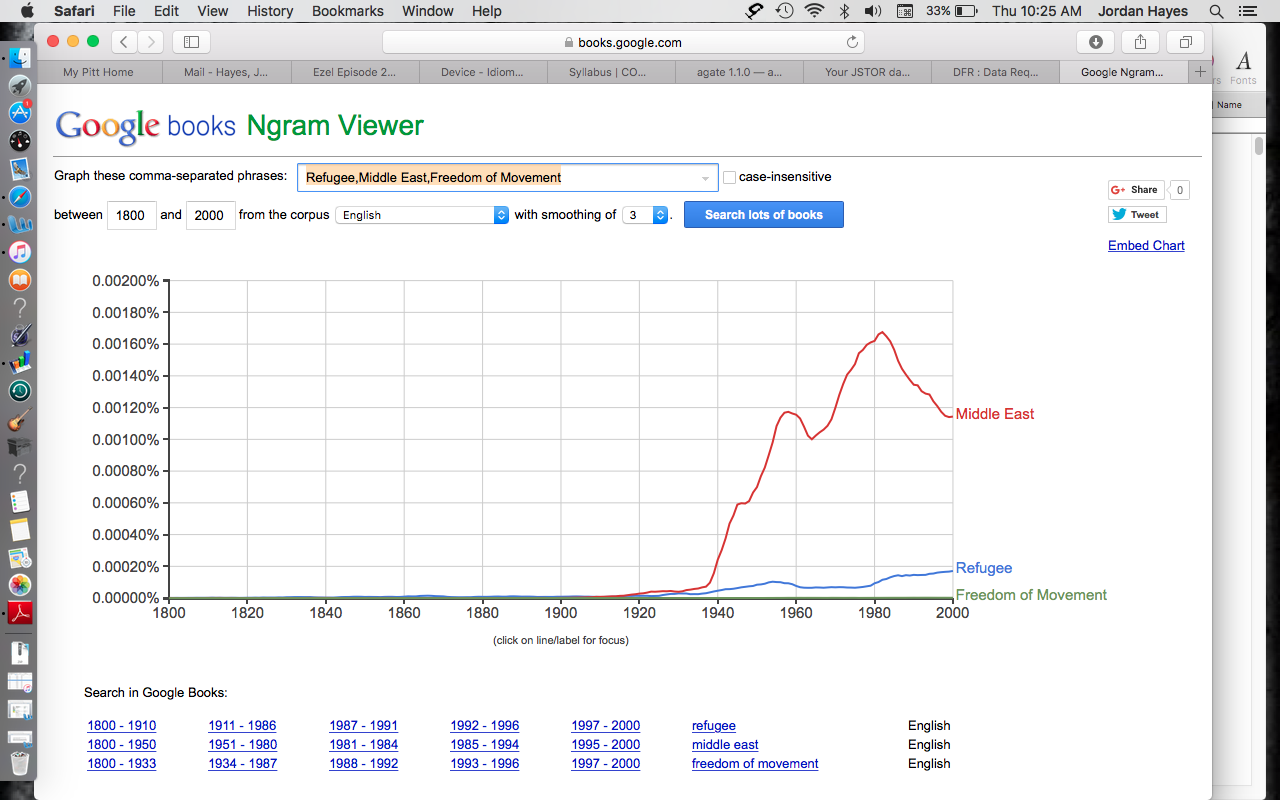
Not that I suppose this is relevant to where we are headed: I see we are generating CSM (Comma Separated Values) data so that we might be able to manipulate it with python, to go beyond the algorithmic features currently built into JSTOR. I suspect this is where I am going to soon be pleasantly befuddled, or at least highly dependent on copying and pasting according to what I hope will be a very, very carefully scaffolded workshop.
I’m aware that the concept of difficulty is operative in this class, and as any good student of  Mariolina Salvatori (formerly of Pitt English) I’m willing to encounter this cognitive-affective state. I would note, however, that the seminal Elements and Pleasures of Difficulty turned on transmuting interpretive difficulty into generative writing, included no computational examples. Perhaps the transposition of this concept to code-based learning merits more explicit theorization.
Mariolina Salvatori (formerly of Pitt English) I’m willing to encounter this cognitive-affective state. I would note, however, that the seminal Elements and Pleasures of Difficulty turned on transmuting interpretive difficulty into generative writing, included no computational examples. Perhaps the transposition of this concept to code-based learning merits more explicit theorization.